Remote Development With Codespaces
Are you tired of spending hours setting up your local machine so you can work with a new repository? Is Docker hogging CPU and memory, killing the promise of...

In the post, we will explore how we can use partitions to reduce job execution time by increasing parallelism. Specifically, we will focus on building Spark partitions from tables in a Postgres database.
Spark is an analytics engine for processing large datasets. Spark allows you to process enormous datasets across many distributed nodes. Distributing processing helps to solve two problems. First, a single node can house a finite amount of memory; for example, a commodity motherboard will only support 256GB of memory. So to process a large dataset, we need a method to distribute data across many nodes. Second, we can speed up processing by harnessing the computing power of many nodes through parallel execution.
In Spark, a partition is a chunk of data stored in a node. All of the tuples in a partition are guaranteed to reside on the same physical node. Partitions form the basic unit of parallelism in Spark.
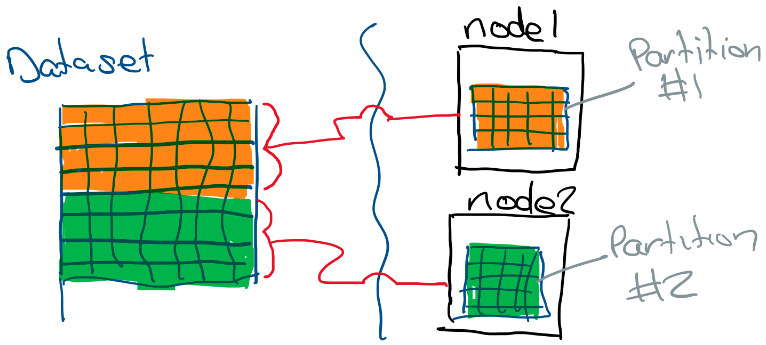
To gain a better intuition on how partitions work with Spark and Postgres, we will build on our Spark/Postgres/Jupyter Docker environment described in my previous post.
The large dataset we will be using is some airline flight delay data from 2008.
First, let’s create a local development environment for testing:
# Clone the repo
git clone https://github.com/omahoco/spark-postgres.git
# Create and start the environment
cd spark-postgres
make all
The flight delay dataset has a couple of interesting columns we can use for our example.
| Column | Description | Type |
|---|---|---|
| FlightDate | The date the flight departed | Timestamp |
| TailNum | A flight identifier | Text |
| ArrDelay | Number of minutes late | Decimal |
To load our sample dataset into Postgres:
make load_airline_data
Next, we open Jupyter http://localhost:9999 and calculate average delays for a given flight using the code below.
import pyspark
conf = pyspark.SparkConf().setAppName('DelayedFlight1Partition').setMaster('spark://spark:7077')
sc = pyspark.SparkContext(conf=conf)
session = pyspark.sql.SparkSession(sc)
jdbc_url = 'jdbc:postgresql://postgres/postgres'
connection_properties = {
'user': 'postgres',
'password': 'postgres',
'driver': 'org.postgresql.Driver',
'stringtype': 'unspecified'}
df = session.read.jdbc(jdbc_url,'public.airline_delayed_flight',properties=connection_properties)
df.groupBy("TailNum").avg("ArrDelay").show()
sc.stop()
The code above hasn’t specified the number of partitions to use; Spark will default to a single partition. You can confirm the number of partitions for yourself with df.rdd.getNumPartitions()). Spark will build the partition by issuing the following query to Postgres:
SELECT "tailnum","arrdelay" FROM public.airline_delayed_flight
The partition will reside in a node and must fit into available memory. We can prove this to ourselves by making the dataset ten times large, which should exhaust memory.
for i in {1..10}; do make load_airline_data; done
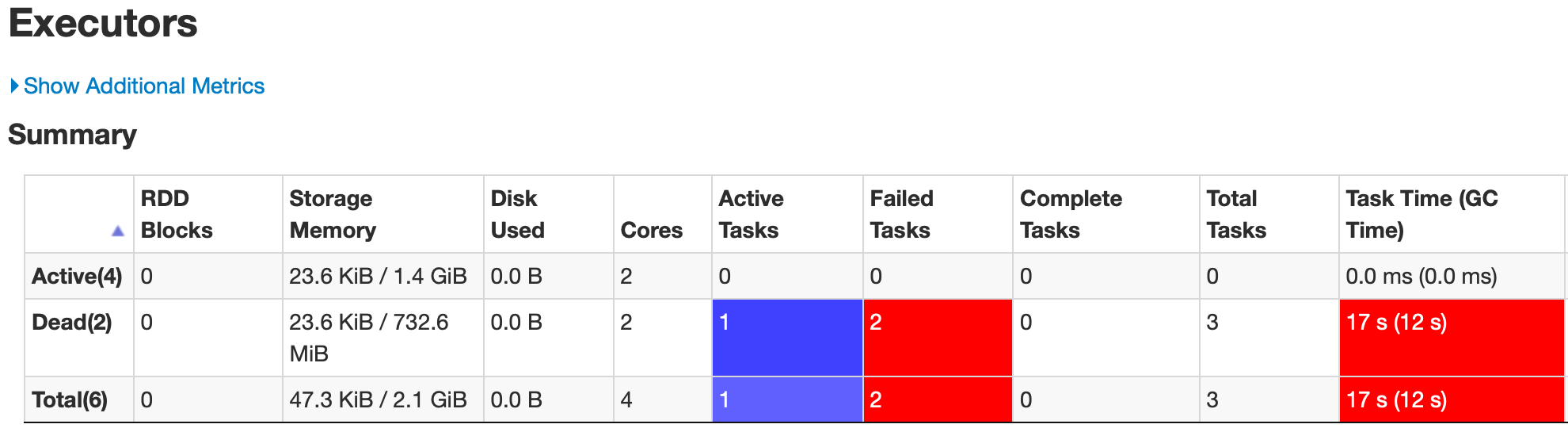
Running the code above will fail after about ~6 minutes. Eventually, we will get the following error:
Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 3, 172.18.0.6, executor 2): ExecutorLostFailure (executor 2 exited caused by one of the running tasks) Reason: Remote RPC client disassociated. Likely due to containers exceeding thresholds, or network issues. Check driver logs for WARN messages.
We can investigate further by looking at the SparkContext Web UI by navigating to http://localhost:4040. From here, we can see that the executor is spending most of the time performing garbage collection.
Now, let’s try to use six partitions to process the dataset. Spark SQL supports partitioned reads using a partitionColumn option. The partition column must be numeric, date or timestamp. The numPartitions parameter works with upperBound and lowerBound to calculate the partition stride.
import pyspark
import datetime
conf = pyspark.SparkConf().setAppName('DelayedFlight6Partitions').setMaster('spark://spark:7077')
sc = pyspark.SparkContext(conf=conf)
session = pyspark.sql.SparkSession(sc)
jdbc_url = 'jdbc:postgresql://postgres/postgres'
jdbcDF = session.read \
.format("jdbc") \
.option("url", "jdbc:postgresql://postgres/postgres") \
.option("dbtable", "public.airline_delayed_flight") \
.option("user", "postgres") \
.option("password", "postgres") \
.option("partitionColumn", "FlightDate") \
.option("lowerBound", datetime.datetime(2008,1,1)) \
.option("upperBound", datetime.datetime(2009,1,1)) \
.option("numPartitions", 6) \
.load()
jdbcDF.groupBy("TailNum").avg("ArrDelay").show()
The code above will create six partitions. Each partition uses a separate database connection and query to retrieve its range. The first and last ranges ensure values below and above the bounds are included.
| Range | Query |
|---|---|
| 1 | WHERE “flightdate” < ‘2008-03-02 00:00:00’ or “flightdate” is null |
| 2 | WHERE “flightdate” >= ‘2008-03-02 00:00:00’ AND “flightdate” < ‘2008-05-02 00:00:00’ |
| 3 | WHERE “flightdate” >= ‘2008-05-02 00:00:00’ AND “flightdate” < ‘2008-07-02 00:00:00’ |
| 4 | WHERE “flightdate” >= ‘2008-07-02 00:00:00’ AND “flightdate” < ‘2008-09-01 00:00:00’ |
| 5 | WHERE “flightdate” >= ‘2008-09-01 00:00:00’ AND “flightdate” < ‘2008-11-01 00:00:00’ |
| 6 | WHERE “flightdate” >= ‘2008-11-01 00:00:00’ |
Are you tired of spending hours setting up your local machine so you can work with a new repository? Is Docker hogging CPU and memory, killing the promise of...
In the post, we will explore how we can use partitions to reduce job execution time by increasing parallelism. Specifically, we will focus on building Spark ...
Aws-azure-login is a command-line utility for organisations using Azure Active Directory to authenticate users to the AWS console. It lets you use an Azure A...